Many areas of cognitive science are attempting to unravel the rich networks of connections between words as interesting approaches to investigating lexical knowledge. However, such enterprises have been hampered by the lack of comparative databases of word associations and suitable network analysis techniques to create semantic network representations. Tokyo Tech's Hiroyuki Akama, Jaeyoung Jung, Maki Miyake, and Terry Joyce have constructed databases of free word associations and have developed original graph clustering techniques to obtain semantic classes within a hierarchical structure.
Akama and his colleagues have proposed a method called recurrent Markov clustering, which avoids limitations inherent in Markov clustering relating to final clusters without common word nodes and the representation of polysemy and provides for improved control of cluster sizes through a recurrent process that uses information about the states of overlapping clusters prior to convergence. When applied to semantic network construction, the recurrent Markov clustering's key feature of being able to adjust for the granularity of a graph allows for modifying the level of conceptual generality in creating hierarchically organized semantic spaces. A report about this research received the Best Paper Award at PACLIC-21.
M. Miyake, T. Joyce, J. Jung, and
H. Akama .
.
Pacific Asia Conference on Language, Information, and Computation-2007 (PACLIC-21), pp. 321–328 (2007).
Department of Human System Science.
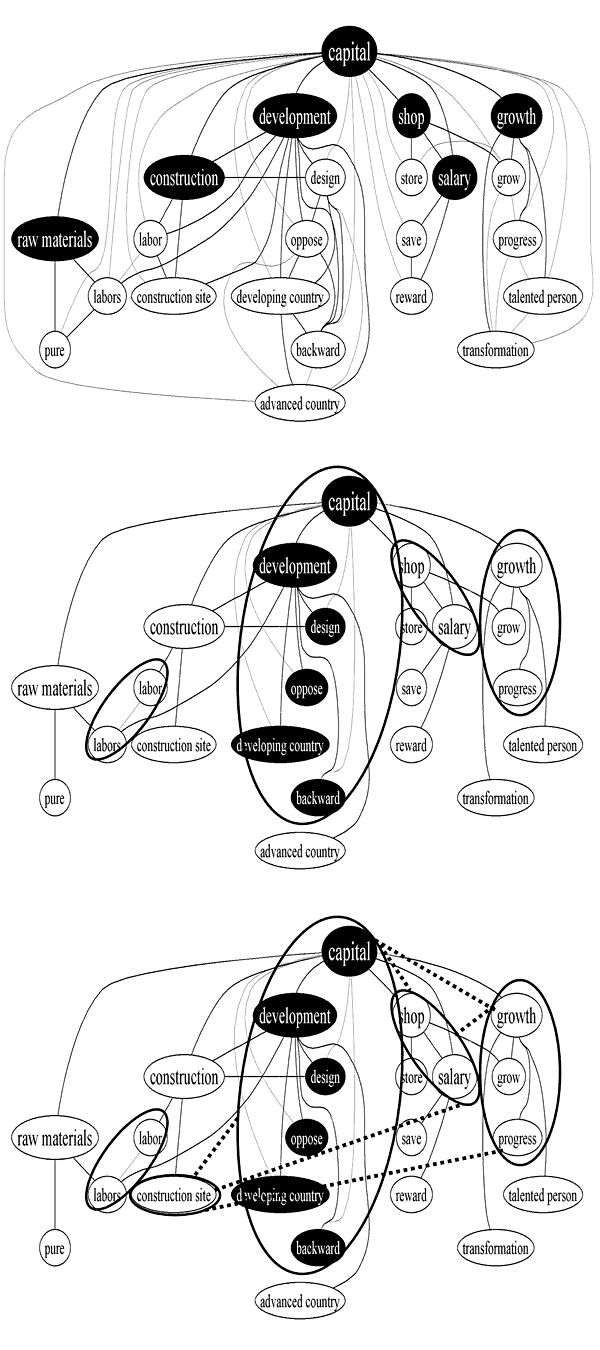
The figures illustrate the recurrent Markov clustering developed by Akama and his colleagues.




