T3 Decoder: A very high-speed, high-performance speech recognizer
Automatic speech recognition (ASR) is the process used to convert spoken utterances into text using a computer. ASR systems usually consist of a voice activity detector (VAD) and a decoder, which uses acoustic and language models. Since state-of-the-art ASR systems are based on statistical models comprising millions of parameters and therefore need a huge amount of computation especially for large-vocabulary continuous speech recognition, it is essential to find effective ways to reduce computational complexity in order to realize real-time systems.
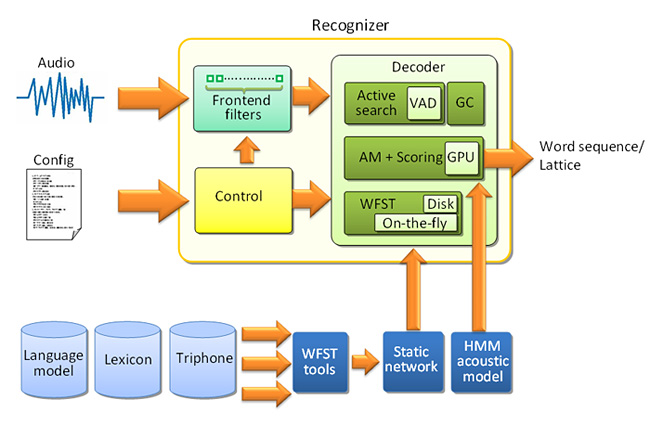
For this purpose, Paul Dixon, Tasuku Oonishi, and Sadaoki Furui have developed a WFST (Weighted Finite-State Transducer)-based decoder, named T3 (Tokyo Tech Transducer-based) Decoder—T3 is read as “T-cubed”. In the T3 decoder, on-the-fly composition is implemented for online transducer update, a commodity Graphics Processing Unit (GPU) is used for decoding, and a VAD is embedded in the decoder (Fig.1). The WFST decoder with on-the-fly composition capability provides a very flexible and efficient decoding structure, the GPU significantly reduces the recognition time, and the VAD-embedded decoder framework achieves high recognition accuracy even for noisy speech. By using these techniques, very fast and accurate ASR systems, such as a real-time high-accuracy continuous speech recognition system with a 500,000 word vocabulary, were achieved.
Reference
- Authors: Paul R. Dixon, Tasuku Oonishi and Sadaoki Furui.
- Title of original paper: Harnessing graphics processors in speech recognition.
- Journal, volume, pages and year: Computer Speech and Language, 23, 510-526 (2009)
- Digital Object identifier (DOI): 10.1016/j.csl.2009.03.005
Affiliations: Department of Computer Science
- Department website: http://www.cs.titech.ac.jp/cs-home-e.html

Structure of an efficient automatic speech recognition system




