



東工大ニュース
東工大ニュース
![]()
公開日:2016.11.21
スパコン向けアプリケーション開発を大幅に容易にする手法を開発
―高性能計算技術の世界最高峰の会議で最優秀論文賞を受賞―
理化学研究所(理研) 計算科学研究機構 プログラム構成モデル研究チームの丸山直也チームリーダーとモハメド・ワヒブ特別研究員、東京工業大学 学術国際情報センターの青木尊之教授の共同研究チームは、ハイ・パフォーマンス・コンピューティング(高性能計算技術)に関する世界最高峰の国際会議であるSC16[用語1]において最優秀論文賞を受賞しました。SC16では442報の論文が投稿され、共同研究チームは「適合格子細分化法[用語2]に関する論文」を投稿しています。
適合格子細分化法はAMRとも呼ばれ、必要な計算およびメモリ使用量を大幅に削減できるため、シミュレーションの高速化に有効です。一方で、大規模なスーパーコンピュータで用いるには、データの移動を無駄なく効率良く行うプログラムなどの開発が必要で、シミュレーションソフトウェアの開発においてさまざまな技術的課題がありました。
共同研究チームは新しいソフトウェア技術を開発し、大規模なスーパーコンピュータ上で簡単に適合格子細分化法を利用できる環境を実現しました。開発したソフトウェアは、プログラムの自動的な変換技術に基づき、従来必要であった煩雑なプログラミングや最適化の多くを自動化します。これによって、シミュレーションソフトウェアの開発コストが大幅に削減されました。GPU[用語3]などのアクセラレータ[用語3]を用いたスーパーコンピュータは性能や省電力に優れるものの、そのプログラミングの手間から使い勝手に劣る点が問題でしたが、開発した手法を用いることで、一般的な適合格子細分化法の利用においては、この問題を解決することができます。SC16での最優秀論文賞の受賞は、共同研究チームの開発内容が国際的に高く評価されたことを示しています。
本研究成果は、SC16の講演要旨集『Proceedings of the ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis (SC'16)』に掲載されます。
本研究の一部は、科学技術振興機構(JST)戦略的創造研究推進事業CREST「ポストペタスケール高性能計算に資するシステムソフトウェア技術の創出」(研究総括:佐藤三久)における研究課題「高性能・高生産性アプリケーションフレームワークによるポストペタスケール高性能計算の実現」(研究代表者:丸山直也)の一環として行われました。
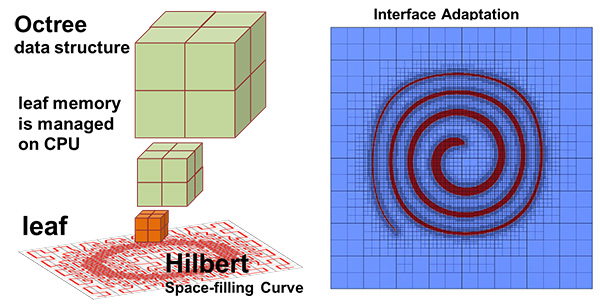
図1. 格子細分化のアルゴリズムと、界面に適合して格子を細分化した計算結果
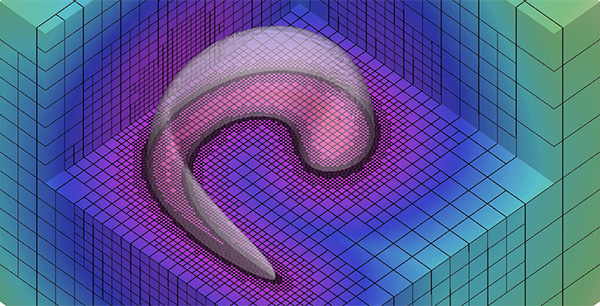
図2. 格子を界面からの距離に応じて細分化することで、高解像度が必要な界面近傍に細かい格子を集めている。
コンピュータを使ったシミュレーションは天気予報から工業製品の設計など社会において幅広く利用されています。特にスーパーコンピュータなどの大規模なコンピュータを使うことで、より高精度・高精細なシミュレーションを高速に行うことが可能になります。一方でコンピュータの性能の向上スピードは次第に鈍化しつつあり、今後、さらにシミュレーションの精度や速度を向上させるためには、シミュレーション手法そのものの改善が、これまで以上に重要になります。
適合格子細分化法はシミュレーションにおいて頻繁に用いられる手法の一つである格子法[用語2]の一種で、通常の格子法に比べて必要な計算およびメモリ使用量を大幅に削減することができます。そのため、原理的にはより高速かつ高精細なシミュレーションが可能になります。しかし、実際に最先端スーパーコンピュータにおいて適合格子細分化法を用いるには多くの課題があります。例えば、最近のコンピュータは計算の性能に比べてデータを移動する性能が低いため、適合格子細分化法によって必要な計算を削減するだけでなく、データの移動を無駄なく効率良く行うプログラムの開発が必要になります。また、GPUなどのアクセラレータを使ったスパコンでは、アクセラレータ用のプログラム開発も必要になります。その結果、適合格子細分化法は原理的に有望な手法であるにも関わらず、実際の利用は通常の格子法に比べて限定的なものになっていました。
共同研究チームは、適合格子細分化法におけるこれまでの問題を解決する新しいソフトウェア技術を開発し、大規模なスーパーコンピュータ上で簡単に適合格子細分化法を利用できる環境を実現しました。開発したソフトウェアは、プログラムの自動的な変換技術に基づき、利用者が作成した適合格子細分化法プログラムからスーパーコンピュータ上で並列に動作する高性能なプログラムを、自動的に作成します。利用者が作成するプログラムはスーパーコンピュータ用に作られている必要がないため、これまでと比較して容易にスーパーコンピュータで適合格子細分化法を使うことができます。通常であればスーパーコンピュータを用いるためには並列化や最適化など、種々の煩雑なプログラミングが必要となりますが、それらの多くが研究チームの開発した手法によって自動化されるため、シミュレーションソフトウェアの開発コストが大幅に削減されました。
実際に開発したソフトウェア技術を、東京工業大学のTSUBAME2.5スーパーコンピュータ[用語4]上で用いたところ、自動的に1,000台規模の多数のGPUを同時に用いた高速かつ大規模なシミュレーションを行うことに成功しました。GPUなどのアクセラレータを用いたスーパーコンピュータは性能や省電力に優れるものの、そのプログラミングの手間から使い勝手に劣る点が問題となっていました。今回の研究結果は、プログラミングを自動化することよってそれらの問題を解決できることを示したものです。
適合格子細分化法に限らず、大規模な最先端のスーパーコンピュータの性能を最大限に引き出すシミュレーションアプリケーションの開発は、次第に困難になりつつあります。今回のSC16では442報の論文が投稿されましたが、これらの問題を解決する共同研究チームの新しいソフトウェア技術が高く評価され、最優秀論文賞を受賞しました。
将来のスーパーコンピュータのハードウェアは、さらなる高性能化のために大きく変わることが想定されています。一方で、アプリケーションプログラムの大幅な書き換えが必要となるなど、利用上の問題が懸念されています。今回、共同研究チームが開発した手法は、原理的には将来のスーパーコンピュータ上でもアプリケーションをそのまま用いることが可能です。そのため、将来のスーパーコンピュータでのシミュレーションを実現する有望なアプローチと考えられています。
共同研究チームは、引き続き開発した手法の改善・改良を続けると同時に、適合格子細分化法に限らず、さまざまな手法で将来のスーパーコンピュータにおけるシミュレーションソフトウェアの開発コストを削減するソフトウェア技術を研究開発していく予定です。
用語説明
[用語1] SC16 : 米国のソルトレイクシティで開催されているHPC(ハイパフォーマンス・コンピューティング:高性能計算技術)に関する国際会議(2016年11月13日~18日)。各種カンファレンス・展示が催されるとともにゴードン・ベル賞・TOP500・Graph500などの表彰も執り行われる。
[用語2] 適合格子細分化法、格子法 : 格子法とは科学技術シミュレーションにおける代表的な手法の一つであり、シミュレーション対象とする空間を格子上に分割し、分割した部分空間ごとに数値方程式に基づいた計算を行う。格子はその間隔を細かく区切るほど計算する部分空間が増大するが、より精緻なシミュレーションが可能になる。適合格子細分化法とはAMRとも呼ばれる格子法の一種。格子の間隔を、物理現象を解像するための必要に応じて適切に調整することによって、より精緻さが求められる領域は細かく、そうでない領域は粗く計算する手法である。例えば自動車の空力をシミュレーションでは、車体表面に接した領域には厚さの薄い境界層が発達するため、格子間隔を密にした計算を行う必要がある。一方で自動車から離れた領域については格子間隔を広くとり簡略化した計算を行う。これにより通常の格子法では必要な精緻さを確保するために均一に格子間隔を細かくする必要があるが、適合格子細分化法では必要な箇所のみ細かく計算することによってシミュレーションの精緻さを損なわずに計算を削減することができる。適合格子細分化法を導入することにより、均一格子での計算と比較して、計算量と使用するメモリの両方ともに1/100 - 1/1,000に低減することができる。
[用語3] GPU、アクセラレータ : コンピュータで用いられるアクセラレータとは計算の一部をCPUに代わってより高速に行う装置である。GPUはGraphics Processing Unitの略であり、当初はコンピュータの画面描画のためのアクセラレータであったが、シミュレーション等の数値計算を行うアクセラレータとしても用いられている。
[用語4] TSUBAME2.5スーパーコンピュータ : 東京工業大学学術国際情報センターに設置されているスーパーコンピュータ。1,400台強の計算機(ノード)から構成され、1台あたり2つのIntel Xeon CPUおよび3つのNVIDIA Tesla GPUを搭載した総演算性能5.7 PFLOPSのクラスタ型システムである。
論文情報
掲載誌 : |
Proceedings of the ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis (SC'16) |
論文タイトル : |
|
著者 : |
Mohamed Wahib Attia, Naoya Maruyama,and Takayuki Aoki |
お問い合わせ先
理化学研究所 計算科学研究機構 研究部門 プログラム構成モデル研究チーム
チームリーダー 丸山直也
特別研究員 モハメド・ワヒブ
E-mail : nmaruyama@riken.jp
Tel : 078-940-5794 / Fax : 078-304-4963
東京工業大学 学術国際情報センター 先端研究部門高性能計算先端応用分野
教授 青木尊之
E-mail : taoki@gsic.titech.ac.jp
Tel : 03-5734-3667 / Fax : 03-5734-3276
取材申し込み先
理化学研究所 計算科学研究推進室
担当 岡田昭彦
E-mail : aics-koho@riken.jp
Tel : 078-940-5625 / Fax : 078-304-4964
理化学研究所 広報室 報道担当
E-mail : ex-press@riken.jp
Tel : 048-467-9272 / Fax : 048-462-4715
東京工業大学 広報センター
E-mail : media@jim.titech.ac.jp
Tel : 03-5734-2975 / Fax : 03-5734-3661
科学技術振興機構 広報課
E-mail : jstkoho@jst.go.jp
Tel : 03-5214-8404 / Fax : 03-5214-8432
