



東工大ニュース
東工大ニュース
![]()
公開日:2012.03.16
東京工業大学理工学研究科の牧野淳一郎教授と一橋大学商学研究科の台坂博准教授らの研究グループは、世界最高の省エネルギー性能を持つ科学技術計算用プロセッサボードを開発した。同研究グループは天文シミュレーション向け計算機「GRAPE-8」(用語1)の開発を進めており、その心臓部となる超低消費電力プロセッサボードを完成したもの。
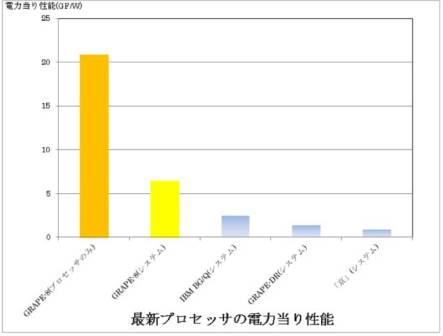
GRAPE-8 プロセッサボード単体はピーク性能が960ギガフロップス(Gflops、用語2)、消費電力はわずか46ワット(W)で、1W当たり20.9G flopsの性能をもつ。このボード2枚を消費電力200Wのパソコンに接続した場合、全体での性能は 1W当たり6.5Gflops となる。プロセッサ本体には 米国eASIC 社の構造化 ASIC(用語3)「Nextreme 2」を使い、開発費を抑えつつ高い省エネ性能を実現した。
従来、汎用計算機で1W当たりの最高性能は IBM「BG/Qシステム」の 2.1Gflopsだったが、GRAPE-8 はその性能を3倍以上上回った。低消費電力化がカギを握る今後のスーパーコンピューティング技術の発展に貢献する成果である。
スーパーコンピュータの性能向上は激しい国際競争があり、1年ないし1年半で2倍というハイペースな進歩が続いている。しかし近年になって、処理性能向上に伴う消費電力の増加が大きな問題になっている。20年前には世界最高速の計算機の消費電力は500kW 程度だったが、最新の「京」は10メガワット(MW) を超える膨大なものになった。このままでは、数年後には計算機本体の費用と、運転費用である電気代が逆転すると予測される。このような状況から、計算機の電力当たり性能を向上させることが、次世代のスーパーコンピュータ開発の最重要課題となっている。
電力当たり性能を向上させるためのアプローチには様々なものがあるが、その中でも大きな効果が期待できるのはアプリケーションに最適化した専用プロセッサに計算の主要な部分を担当させることである。
通常の計算機はソフトウェアによって複雑な計算を実行する。そのために、計算のたびに命令の解釈、制御、演算器とレジスタ、キャッシュメモリなどとのデータの移動といった数多くの操作が行われ、それらが電力を消費する。また計算精度が倍精度と単精度(用語4)の2種類しかないため、ほとんどの演算を必要以上の精度で実行することになり、ここでも大きな無駄が生じる。専用プロセッサでは必要十分な精度をもった演算器を演算順序に従って接続し、流れ作業で計算を進めることで、上の2つの無駄をほぼ0にし、理論的に実現可能な限界まで電力当りの性能を向上させることができる。
GRAPEプロジェクトは、1990 年代初めから専用プロセッサの開発を続けており、開発した計算機を使って天文学研究で成果をあげてきた。しかし半導体技術が進歩するに従って、 LSI開発コストが激増し、専用プロセッサの開発が困難になっていた。
GRAPE-8では、 eASIC社の技術を採用することで安価にLSIを開発した。eASIC社の技術は、従来のゲートアレイによるカスタムLSIと、FPGA(用語5) との中間にあるもので、ロジックセルとその間の配線のプログラムを1層の配線だけをカスタマイズすることで、開発コストを 1/10以下に引き下げることができる。
FPGAでは、ロジックセルの機能、セル間の配線を、SRAMとスイッチによってプログラムすることで「ソフトウェアで変更可能なハードウェア」を実現するが、その代わり回路の集積度、動作速度がカスタムLSIに比べて落ち、消費電力は増加する。 eASIC社の技術ではFPGAに比べて高い集積度、動作速度を低い消費電力で実現でき、またデバイスも回路規模が同程度のFPGAに比べて安価である。
eASIC社の技術を使うことで、 GRAPE-8プロセッサチップは40個近い演算器からなるパイプラインユニットを48個集積し、ほぼ2000個の演算器を250MHz 動作させて480Gflops 相当の演算性能をチップ単体では13Wの消費電力で実現できた。チップ2つとPCI-Express(用語6)インターフェースを搭載したボード全体では46Wの消費電力になる。
チップ単体での電力当り性能は現在世界一の速度をもつ「京」コンピュータのVenusプロセッサの17倍、パソコンまで含めたシステム全体でも8倍と、非常に高い性能を実現した。
今後は GRAPE-8を使って天文学の研究を進めるとともに、より電力当たり性能の高い後継機の開発と、天文学以外へのこのアプローチの応用に取り組んでいく。このように次世代のスーパーコンピュータの課題に取り組み、さらに高い性能を実現していくことで、スーパーコンピュータの発展に寄与していきたいと考えている。
なお本発表は、文部科学省科学研究費補助金(基盤A)、「専用計算機による惑星系・星団・銀河の進化の研究 」で得られた成果に基づくものである。

GRAPE-8 プロセッサボード。
GRAPE-8 チップ2つ(両側)と制御・インターフェース用のFPGAチップ(中央)を搭載する。
●用語説明
GRAPE-8: 東工大・一橋大学が共同開発した、天文シミュレーション用スーパーコンピューターシステム。銀河系や星団のような、多数の粒子がお互いの重力を受けて運動している系のシミュレーションに特化した加速ボードを通常のPCクラスタに付加することで、高い性能と電力当り性能を実現する。
ギガフロップス(Gflops): 計算機の速度の単位。1秒間に10億回の浮動小数点計算(加算と乗算の合計で)を実行した時の速度。
構造化ASIC: LSIの種類の一つ。 通常のカスタムLSIチップの設計ではでは、トランジスタと多数の配線層の全てを専用に設計するが、例えば配線層1層だけを専用設計にし、その他の部分は共通化することで初期コストを引き下げ、少量生産を可能にする技術。
倍精度と単精度: 科学技術計算で使う浮動小数点数の精度の種類。倍精度は64ビットを使い、10進数で16桁程度の精度がある。単精度は32ビットで、7桁程度である。
FPGA: Field Programmable Gate Array の略。論理素子の機能と論理素子間の配線を、SRAMメモリ等によって書き換え可能にすることで、製造してから機能をカスタマイズできる LSIのこと。通常のカスタムLSIに比べて速度、消費電力、回路規模で劣るが、初期コストは低い。
PCI-Express: 最近のパソコンの拡張ボードのための標準的なインターフェース。
本件に関するお問い合せ先
牧野淳一郎
大学院理工学研究科 共通講座 教授
電話: 03-5734-3984
FAX: 03-5734-3538
E-mail: makino@geo.titech.ac.jp
